恶意代码 new
发现的新东西 )
)
恶意代码检测基础知识
Malware:恶意软件
Malicious Code:恶意代码
Malware Detection
Malicious Code Detection
"恶.意软件检测"和"恶意代码检测"是在计算机安全领域中两个相关但略有不同的概念。
恶意软件检测:
- 定义: 恶意软件检测是指识别计算机系统中是否存在任何形式的恶意软件,包括病毒、蠕虫、木马、间谍软件、广告软件等。
- 范围: 这一概念更为广泛,它关注的是整个恶意软件的存在和活动,而不仅仅是其代码。恶意软件可能以文件、进程、注册表项等形式存在,并可能涉及多个组件。
恶意代码检测:
- 定义: 恶意代码检测更侧重于发现和分析特定的恶意计算机代码。这可以包括对恶意软件中的具体代码片段、脚本或二进制文件的分析和识别。
- 范围: 而恶意代码检测更关注于检测和分析在系统或应用程序中存在的具体、恶意的计算机代码。这可能包括检测恶意代码的签名、行为模式、漏洞利用等方面。
总体来说,恶意软件检测更注重对整个恶意软件实体的检测,而恶意代码检测更专注于具体的恶意代码片段的检测和分析。在实际操作中,这两者通常相互结合,以提供更全面的安全保护。安全软件和系统通常使用恶意软件检测引擎和恶意代码分析引擎来协同工作,以检测和应对各种安全威胁。
在谷歌学术里搜2023年以来,
malware detection Android有3900条结果,malware detection IoT有7700条结果
评论性文章分别有583和1720条
常见恶意代码行为
- 下载器、启动器:从网络下载运行恶意代码
- 后门
- 登录凭证窃密器
- 存活机制
- 提权
- 隐藏踪迹
静态分析技术:
对恶意代码进行逆向工程,对程序文件的反汇编代码、图形图像、可打印字符串和其他磁盘资源进行分析。学习曲线陡峭(汇编语言、代码结构、操作系统等等)
- windows可移植可执行文件(Portable Executable,PE)是一种用于 32 位和 64 位版本的 Windows 操作系统的可执行文件格式。PE 文件包括可执行文件(.exe)、动态链接库(.dll)以及一些其他文件类型。
- dll文件和看起来和exe文件几乎一模一样,dll使用PE文件格式,并且只有一个单一的标志指示这个文件是dll
限制静态分析的因素
- 加壳:软件压缩、加密或其他方式破坏程序主体,程序运行时才会自动解包开始执行,很明显绕过加壳的方法就是动态检测技术
- 资源混淆:混淆字符串、图形图像等资源存储在磁盘上的方式,程序运行时才将其还原
- 反汇编:
- 动态下载数据:从外部服务器获取数据和代码
动态分析技术
恶意软件检测的动态分析技术是一种通过观察程序在运行时的行为来检测潜在的恶意活动的方法。与静态分析技术不同,动态分析关注的是程序在执行时的实际行为,这使得它能够捕捉到恶意软件的行为特征和模式。
在独立环境中运行恶意代码,观察其行为。并非对所有恶意代码有效。
使用沙箱检查运行时刻的内部状态,包括:
- 分析文件摘要(文件名,日期,md5、shaXXX(哈希算法生成的哈希值))
- 文件活动
- 互斥量创建
- 注册表和更改系统配置
- 网络行为
- api调用
机器学习IN恶意代码检测
卡巴斯基网站里的,网络安全中的机器学习
#恶意代码检测 #机器学习 #网络安全
Machine Learning in Cybersecurity | Kaspersky
Decision tree ensembles, locality sensitive hashing, behavioral models or incoming stream clustering - all our machine-learning (ML) methods are designed to meet real world security requirements: low false positive rate, interpretability and robustness to a potential adversary.决策树集成、局部敏感散列、行为模型或传入流聚类——我们所有的机器学习(ML)方法都是为了满足现实世界的安全要求而设计的:低误报率、可解释性和对潜在对手的鲁棒性。
- 内容:机器学习
- 部分内容:
人工智能先驱阿瑟·塞缪尔 (Arthur Samuel) 将机器学习描述为一组方法和技术,“赋予计算机无需明确编程的学习能力”。 在反恶意软件监督学习的特定情况下,任务可以表述如下:给定一组对象特征 X 和相应的对象标签 Y 作为输入,创建一个模型,该模型将为以前未见过的生成正确的标签 Y' 测试对象X'。 X 可以是代表文件内容或行为的一些特征(文件统计信息、使用的 API 函数列表等),标签 Y 可以只是“恶意软件”或“良性”(在更复杂的情况下,我们可能对精细的 - 细粒度分类,例如病毒、木马下载程序、广告软件等)。 在无监督学习的情况下,我们更感兴趣的是揭示数据的隐藏结构 - 例如,查找相似对象组或高度相关的特征。
卡巴斯基实验室端点产品中使用的一些最重要的基于机器学习的技术:
- 决策树集成
在这种方法中,预测模型采用一组决策树的形式(例如随机森林或梯度提升树)。 树的每个非叶节点都包含一些有关文件特征的问题,而叶节点包含树对对象的最终决策。 在测试阶段,模型通过回答具有所考虑对象的相应特征的节点中的问题来遍历树。 在最后阶段,以特定于算法的方式对多棵树的决策进行平均,以提供对对象的最终决策。
该模型有利于端点站点上的执行前主动保护阶段。 我们这项技术的应用之一是用于移动威胁检测的 Android 版 Cloud ML。
- 相似性哈希(局部敏感哈希)
过去用于创建恶意软件“足迹”的哈希对文件中的每一个微小变化都很敏感。 恶意软件编写者通过服务器端多态性等混淆技术利用了这一缺陷:恶意软件的微小变化使其不再受到关注。 相似性哈希(或局部敏感哈希)是一种检测相似恶意文件的方法。 为此,系统提取文件特征并使用正交投影学习来选择最重要的特征。 然后应用基于机器学习的压缩,以便将相似特征的值向量转换为相似或相同的模式。 该方法提供了良好的泛化性,并显着减小了检测记录库的大小,因为现在一条记录可以检测整个多态恶意软件家族。
该模型有利于端点站点上的执行前主动保护阶段。 它应用于我们的相似性哈希检测系统(Similarity Hash Detection System)。
- 行为模型
监控组件提供行为日志 - 流程执行期间发生的系统事件序列以及相应的参数。 为了检测观察到的日志数据中的恶意活动,我们的模型将获得的事件序列压缩为一组二进制向量,并训练深度神经网络来区分干净的日志和恶意的日志。
行为模型进行的对象分类由端点侧卡巴斯基产品中的静态和动态检测模块使用。
在构建适当的实验室内恶意软件处理基础设施时,机器学习发挥着同样重要的作用。 卡巴斯基实验室将其用于以下基础设施目的:
- 传入流聚类
基于机器学习的聚类算法使我们能够有效地将进入我们基础设施的大量未知文件分成合理数量的集群,其中一些集群可以根据其中是否存在已注释的对象来自动处理。
- 大规模分类模型
一些最强大的分类模型(如巨大的随机决策森林)需要大量资源(处理器时间、内存)以及昂贵的特征提取器(例如,详细的行为日志可能需要通过沙箱进行处理)。因此,更有效的方法是在实验室中保存和运行模型,然后通过根据更大模型的输出决策训练一些轻量级分类模型来提取这些模型获得的知识。
- 机器学习的安全性
机器学习算法一旦脱离实验室并引入现实世界,就可能容易受到多种形式的攻击,这些攻击旨在迫使机器学习系统犯故意错误。攻击者可以毒害训练数据集或对模型代码进行逆向工程。此外,黑客还可以使用专门开发的“对抗性人工智能”对机器学习模型进行“暴力破解”,自动生成许多攻击样本,直到发现模型的弱点。此类攻击对基于机器学习的反恶意软件系统的影响可能是毁灭性的:错误识别的特洛伊木马意味着数百万台设备受到感染,并造成数百万美元的损失。
因此,在安全系统中使用机器学习时应考虑一些关键因素:
- 安全供应商应了解并仔细解决真实的、可能充满敌意的世界中机器学习性能的基本要求,其中包括对潜在对手的鲁棒性。ML/AI 特定的安全审计和“红队”应该是 ML/AI 开发的关键组成部分。
- 在评估 ML 解决方案的安全性时,应该询问解决方案对第三方数据和架构的依赖程度,因为许多攻击都是基于第三方输入(我们谈论的是威胁情报源、公共数据集、预经过训练和外包的 ML 模型)。
- 机器学习方法不应被视为“最终答案”。它们需要成为多层安全方法的一部分,在这种方法中,互补的保护技术和人类专业知识一起工作,互相照顾。
有关 ML 算法的流行攻击以及防范这些威胁的方法的更详细概述,请参阅我们的白皮书“受到攻击的人工智能:如何在安全系统中保护机器学习”。
机器学习在恶意软件检测中的应用
#建瓯最坏 的论文笔记(他应该觉得这篇文章很重要):中国科学院信息工程研究所-李策 - 机器学习在恶意软件检测中的应用
来源:机器学习在恶意软件检测中的应用 - 安全内参 | 决策者的网络安全知识库
作者:李策 中国科学院信息工程研究所
1、引言
随着社会发展越来越依赖于计算机系统和网络技术,恶意软件对于当今社会的威胁越来越大。恶意软件检测一直是网络安全学术界和工业界长期致力于解决的关键问题。
传统的恶意软件方法依赖威胁情报库,即将软件的特征与情报库中的情报做信息匹配。然而,这种威胁情报库的维护成本很大,并且需要大量的专家知识,而且随着恶意软件向着载荷小、隐蔽性高、危害性大、变体繁杂等方向持续进化,特别是现在很多黑客组织直接采用脚本生成大批量的恶意软件从而进行大规模恶意软件攻击,传统依赖于规则匹配的方法很难再适用于当下的网络安全环境。
近几年,随着大数据和机器学习的大规模发展,越来越多的网络安全人员尝试使用机器学习的方式学习恶意软件与正常软件的特征,从而让恶意软件检测工作摆脱威胁情报和专家知识,并且能够从容应对大规模的恶意软件攻击。
2、背景
随着计算机系统和网络技术的大规模应用,恶意软件的危害也变得尤为突出。网络蠕虫、勒索软件等入侵事件愈演愈烈,黑客组织往往采用脚本生成大量同类恶意软件的变体从而进行大规模的网络攻击,导致社会各界损失惨重。
根据Gantz等人的研究[1],仅2014年隐藏在盗版软件中的恶意软件,就造成了接近5000亿美元的经济损失,这还只是众多类型恶意软件的冰山一角。
根据AV-TEST的统计[2],在2019到2020年期间,各大安全厂商上报的恶意软件中,就有超过1.14个恶意软件没有被最新的威胁情报记录在案,而仅仅是在2020年的第一季度,就发现了超过4.3亿个新型恶意软件。
显然,在当今的网络环境下,恶意软件攻击是复杂多变的。仅仅依靠传统的规则特征匹配不仅需要大量的专家知识维护情报库,而且往往对新出现的恶意软件变体无可奈何。
应用机器学习算法,根据恶意软件的行为特征来检测恶意软件似乎是解决这一问题的可能途径。
事实上,早在1995年就有人产生过将机器学习应用于恶意软件检测的想法[3]。但是因为要训练一个好用的机器学习模型,必须要有足够数量和质量的数据集做支撑,但在当时还没有大数据的概念,恶意软件的可用样本也比较少,难以让模型真正有效地学习到相应的特征。
近几年,由于恶意软件的数量激增,研究人员可以收集到大规模的恶意软件样本,并由此对机器学习甚至是深度学习模型的训练提供良好的数据支撑。(双押了)
并且除了统计机器学习模型外,深度学习如卷积神经网络、循环神经网络、图神经网络等算法的蓬勃发展,也为研究人员提供了更好的选择。
在这种背景下,越来越多的安全研究人员设计针对恶意软件检测的特征工程,并把多种机器学习算法应用于恶意软件检测,最终达到了非常好的效果。
值得一提的是,由于机器学习方法不依赖于专家知识和威胁情报,而且是通过学习恶意软件的特征来给出评判结果,所以这种方式可以在成本小的前提下对于变体恶意软件具有良好的判别力。
3 方法
虽然恶意软件检测问题涉及多种文件格式和操作系统,但在大多数情况下,同样的特征工程和方法也适用于其他恶意软件领域,例如适用于windows系统可执行文件(PE)的检测算法也同样适用于恶意PDF文件,Linux或Android平台的恶意软件。本文将基于机器学习的恶意软件检测方法按照所需要的特征和模型分为主要的四类,并分别概述具有代表性方法。
3.1 基于统计特征的方法
被广泛使用的特征工程项目LIEF[4]根据解析二进制文件的头部和节的相关信息提取多维特征,包含文件字节码特征、导入表信息、文件各个部分的熵值等信息,共同组成一个特征向量,作为被检测文件的画像。基于这种特征提取方式,研究人员大多采用一些统计机器学习模型如决策树、支持向量机、集成学习等进行有监督训练,并最终达到区分良性软件与恶意软件的目的,此类方法的大致流程如图-1所示。
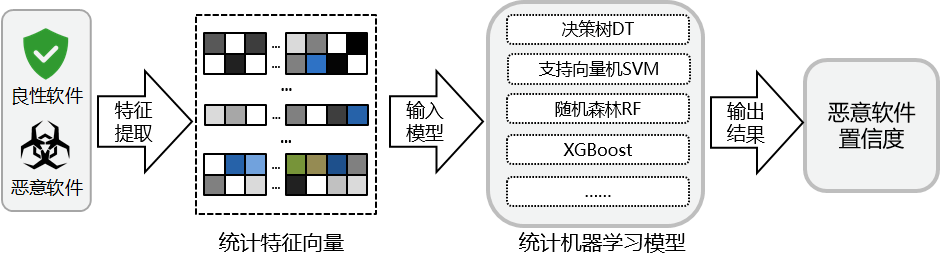
图-1 基于统计特征的方法流程图
3.2 基于指纹图的方法
此类方法的大致流程如图-2所示。由于软件样本本身是二进制文件,而一个字节(八位二进制数)的大小范围为0-255,也就是一个像素的取值范围。所以在特征提取阶段可以将二进制可执行文件按照八位一个像素值转化为一个“指纹灰度图”,这样恶意软件检测问题就变成了一个对指纹图的学习和分类问题。而在深度学习领域,计算机视觉领域的卷积神经网络(Convolutional Neural Networks, CNNs)十分擅长对图片进行学习。
所以,安全人员将指纹图输入到各种卷积神经网络,并输出恶意软件置信度,最终判断输入样本是否为恶意软件。代表工作MalConv[5]就是利用这种方式可以在大规模恶意软件检测任务中达到90%以上的检测准确率。
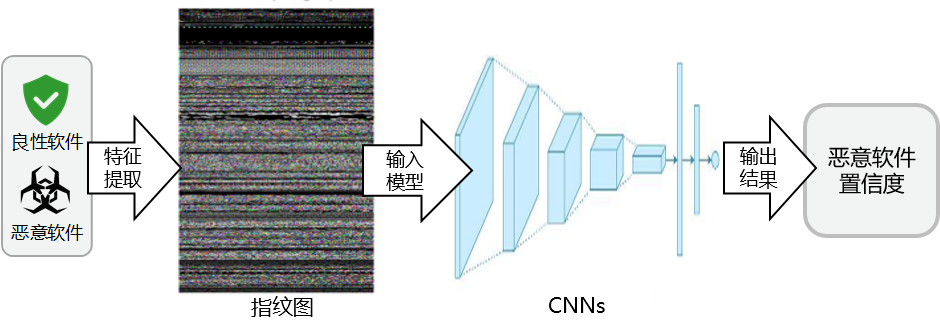
图-2 基于指纹图的方法流程图
3.3 基于API调用序列的方法
相对于基于统计特征和指纹图的方法,基于API调用序列的方法旨在让模型真正学到软件所暴露的恶意行为,并以此为特征来判别恶意软件。
这类方法的流程图如图-3所示。首先在特征提取阶段,相比于基于统计特征和指纹图这些直接在文件中提取特征的方法,基于API调用序列的方法往往要真正地运行软件样本,并监控软件所对应的进程,提取该软件在运行过程中所调用的系统API,用这些API所组成的序列作为特征来表示软件运行过程中的各种操作,进而表示软件的行为。
为了更加有效的获取API调用序列,研究人员往往在沙箱中运行软件样本,成熟的沙箱系统如Cuckoo[6]提供了安全的软件执行环境,并且会自动化地监控软件运行所对应进程的API调用信息。在获取到API调用序列之后,就要考虑如何让模型“理解”这段序列并做出判断。
一个合理的解决方案是把API调用序列中的每个API看做是一个词,那么整个序列就可以看做是一句话,这样就可以使用自然语言处理领域的多种模型来解决这个问题。在自然语言处理领域,以循环神经网络(Recurrent Neural Networks, RNNs)为代表的的多种模型取得了巨大的成功。
安全人员尝试借鉴自然语言处理领域的各种特征编码和模型来分析API调用序列,并在大规模恶意软件检测任务中可以达到97%以上的检测准确率[7]:
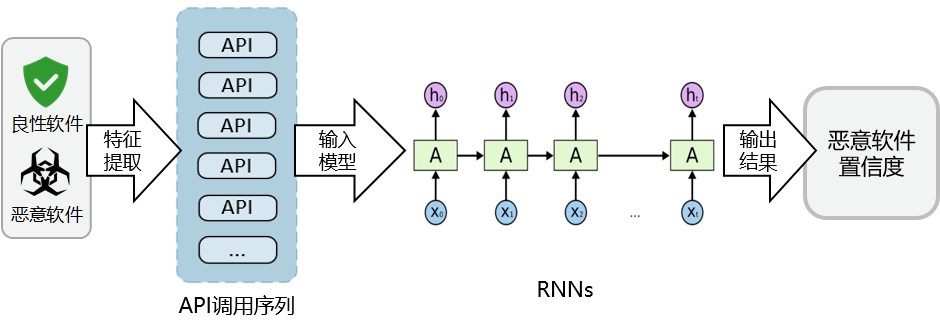
图-3 基于API调用序列的方法流程图
3.4 基于程序执行流程图的方法
这类方法的流程如图-4所示。控制流图是非常熟知的特征,研究人员通过反汇编将二进制软件样本转化为汇编代码,并从中提取控制流图,从而转化为一个图分类问题。
近年来图神经网络(Graph Neural Networks,GNNs)的蓬勃发展为解决这类问题提供了新的思路。代表工作[8]和[9]都使用了图神经网络来分析控制流图,并在大规模数据集中可以达到95%以上的准确率。

图-4 基于程序执行流程的方法流程图
4 挑战
虽然机器学习在恶意软件检测方面已经取得了非常可观的效果,但是由于机器学习本身的一些原因,这些方法还是存在一些问题,而这也导致了在工业界机器学习并没有进行大规模的普遍使用,这里介绍三个主要的问题。
第一个比较核心的问题就是机器学习模型的鲁棒性问题,因为这种模式毕竟是数据驱动的,在数据集上得出的结论往往会与现实世界有偏差,极高准确率下的检测结果往往是由于模型对于数据的过拟合造成的,这样的模型一旦投入生产反而会成为黑客组织攻击的对象。所以如何提高模型鲁棒性泛化性也是学术界一直在探讨的热点问题。
第二个问题是机器学习可解释性的问题。众所周知,很多机器学习模型是按照端到端的模式设计的,这样的模型对于使用者和维护者来说就是一个黑盒,人们无法理解模型到底是凭借什么做出的决策,又该朝着什么方向去优化,这使得机器学习往往在网络安全产品层面给人一种泡沫感。
第三个问题是概念漂移的问题。由于恶意软件是随着时间不断进化的,所以通过现有数据集训练好的机器学习模型可能在未来某个时候会不再适用,而重新训练模型往往伴随着巨大的成本。所以如何在低成本的条件下让模型持久使用也是一个亟待解决的问题。
5 小结
在大数据时代下,传统基于规则的恶意软件检测方法能力有限,将机器学习应用于恶意软件检测会在不依赖专家知识的条件下取得较好的效果。然而由于机器学习本身的一些问题目前并没有很系统的解决方案,所以现阶段这种模型也只是小规模地应用在工业界,绝大多数网络安全产品往往采用传统方法与机器学习方法相结合的模式。
因此,现阶段其实处在一个技术过渡与发展的时期,恶意软件检测是一个复杂而长期的问题,充满着机遇与挑战。
物联网恶意代码检测
物联网学习笔记:物联网相关笔记